

【内容摘要】文章一方面叙述西藏的多样性语言现象,另一方面尝试用一种计算机自动聚类方法对西藏的语言进行分类。文章采用编辑距离计算方法的编码和赋值,以及聚类算法和树形图呈现。实验采集了西藏的藏语及其方言,还有门巴、珞巴、僜人等族群的非藏语语言共计49种,包括目前尚未识别的一些地方话。实验结果表明:西藏地区分布着藏语和非藏语的藏缅语,藏语包括传统分类的卫藏和康方言,卫藏又可分为前藏、后藏、阿里和南部次方言;非藏语的藏缅语有门巴族语言、珞巴族语言、义都系语言,以及藏东和藏东南语言系属不明的地方话。与传统分类相比,文章中所用机器语言或方言自动分类相当合理,可信度很高。
【关键词】西藏;语言多样性;编辑距离;自动分类
【作者简介】江荻,江苏师范大学语言科学与艺术学院汉语和汉藏语研究中心特聘教授、中国社会科学院民族学与人类学研究所研究员。
【文章来源】《中国藏学》2022年第6期。
【中图分类号】H429
【文献标识码】A
【文章编号】1002-557(A)(2022)06-0150-11
一、引言
藏语在中国分为三大方言,卫藏方言、康方言和安多方言,其中卫藏方言和相当多的康方言分布在西藏自治区。西藏东南部连接着中国民族走廊的南端,除藏语外,还有多语言分布。费孝通先生提出:“把北自甘肃,南到西藏东南的察隅、洛渝这一带地区全面联系起来,分析研究靠近藏族地区这个走廊的历史、地理、语言并和已经陆续暴露出来的民族识别问题结合起来……洛渝各民族集团的语言据初步了解不属藏语支而与景颇语支相近。如果联系到上述甘南、川西的一些近于羌语和独龙语的民族集团来看,这一条夹在藏彝之间的走廊,其南端可能一直绕到察隅和洛渝。”这种见解之深刻,对我们深入了解藏语跟周边藏缅语言之间关系具有重要价值。
地理上,大致在林芝市工布江达县及以东区域,特别是藏东南地区还有数量不明的非藏语语言,有些已经甄别,例如错那县的门巴语,墨脱县的仓洛语,米林县的博嘎尔语,隆子县的苏龙语,察隅县的义都语、达让语、格曼语等。但是还有一些地方话尚需进一步甄别,例如工布江达县错高乡巴松话、芒康县如美镇的如美话、左贡县东坝乡的东坝话、察隅县的扎话和素苦话等。这些说话人有些是藏族人,有些人长期与藏族人民生活在同一区域,从小习得母语和藏语,他们基本都是双语人或多语人,因为受藏语影响,即使他们在家里说母语的时候也使用大量藏语借词。
除了藏语和汉语有传统文字记载,西藏地区其他各种语言都没有书面文字。判定这些语言是否为独立语言及这些语言的语系归属是很专业的事情,通常需要投入很大的人力和物力资源才能有所判断。判断新发现语言的语系地位一般采用历史语言学的比较方法,通过词汇语音和形态比较找出语音对应规律,确定同源词,再进一步确定语言之间的关系。这其中的一个难点是排除各个语言中的外来语借词,具体说,藏语是西藏通行的地方通用语言,其他语言都受到藏语的影响,甚至是深度影响,借入了大量藏语词汇和句法结构。鉴于这一现状,本文采用一种计算机新的算法技术对西藏各地语言和方言进行自动聚类分析,尝试快速准确地对这些语言和方言进行分类。然后,借助历史比较方法进一步考察和验证本文聚类算法的结果,判断其是否与语言学分类结果一致,是否与人们习惯的分类认知一致。
二、语言和方言材料
语言聚类分析以采集的语言材料为实验对象,一般是词汇数据,又可分为声音材料和记音材料。前者是词语的录音声学参数,例如音值(音素)、音高(音频)、音长(时长)等,后者是音标符号记录的书面形式。本文以音标记录的语音形式为实验对象。
本文依据语言研究的常规经验和所采用的数学方法和算法模型,确定采用斯瓦迪士基本核心词表,该表收纳客观世界基本概念义100项,即100个核心词。经过世界各国语言学家和心理学家实践和验证,该词表在有效性和可信度等各方面经证明是可靠和可用的。
本文运用多种方法开展实际语料的采集,一部分是实地记音和录音;一部分选自出版的书刊;还有一部分采自中国语言资源保护工程(网络平台)。具体语言分布地点如下(括号内为方言调查点数量)。
前藏(6):拉萨、墨竹工卡、林周、尼木、泽当、乃东;
后藏(8):日喀则、浪卡子、亚东、吉隆、定结、洛扎、樟木、夏尔巴;
阿里(7):噶尔、日土、普兰、札达、革吉、措勤、改则;
藏东(10):昌都、丁青、那曲、安多(帕那)、工布江达、八宿、索县、墨脱(达木)、错那、察隅。
以上藏语方言点已经按照传统分类观点进行了预分类,包含地理分布分类思想,共有31个方言点,又分出前藏、后藏、阿里、藏东4个地理区域。
非藏语语言主要分布在藏东和藏东南区域,以下仅按照语言名或地理位置加语言名罗列。又分为已识别为独立语言的和尚需甄别是否为独立语言的。
识别为独立语言或方言的有11种:门巴语麻玛话、门巴语文浪话、仓洛语地东话、义都语上察隅话、达让语夏尼话、格曼语萨穹话、混合语察隅扎话、崩尼语斗玉话、崩如语三安曲林话、博嘎尔语南伊话、苏龙语。
待识别的语言有7种:工布江达错高乡巴松话、左贡县拉茸话、芒康县如美话、察隅县素苦话、左贡县东坝话、察隅县松林话、察雅县芒话和玛吉话。
三、数据编码和赋值
前文已经指出,本文以音标记录的斯瓦迪士核心词为实验材料,借助计算机算法开展不同语言或方言之间亲疏远近关系及其自动分类研究,本节讨论拟采用的数学模型及编码和赋值操作。
字符或音标符号记录的词语形式自然而然反映出人类声音的线性序列特征,例如拉萨话[ȵi11ma55]、日喀则话[ni11ma53]都表示“太阳”的意思,呈现出两个音节,每个音节都是辅音—元音序列和结构,这种结构十分适合采用编辑距离(edit distance)模型计算。由于这个算法是俄罗斯数学家弗拉基米尔·莱文斯坦(Vladimir Levenshtein)提出的,因此多称莱文斯坦距离(Levenshtein Distance)。一般的定义是:莱文斯坦距离是测量两个字符串之间差异的数学模型。从应用上说,人们可以利用莱文斯坦距离比较两个字符串的相似度。如果承认语言和方言之间存在历史演变关系,则可以将不同语言或方言之间词语的相似度理解为语言演变的亲缘远近关系。具体操作上,人们假设两个词语之间的莱文斯坦距离是将一个词形更改为另一个词所需要的最小操作步骤。不妨举例说明。
以英语方言为例,afternoon在Savannah镇(美国佐治亚州)发音是[ˈæəftənʉn],而在Lancaster镇(美国宾夕法尼亚州)发音是[ˌæftərˈnuˑn]。如果把Savannah发音转换为Lancaster一样的发音,这中间的操作就是二者的相似度差别。莱文斯坦距离测算的方法是以处理符号的操作次数作为量化数值,它规定了3种操作:插入、删除和替换,每次操作数值记为1。本文操作不纳入韵律要素,例如重音、次重音和半长音(“uˑ”,Lancaster镇)。
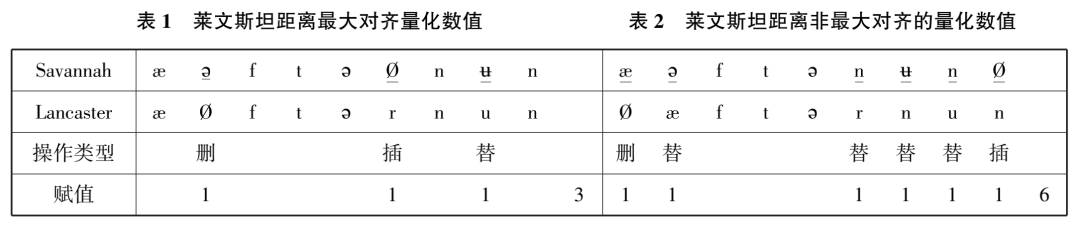
莱文斯坦距离采用最大字符对齐方法,表1是最佳的最小操作次数,赋值3。表2未采用最大对齐方法,赋值6,显然不是可选的方案。
莱文斯坦距离计算公式如下:
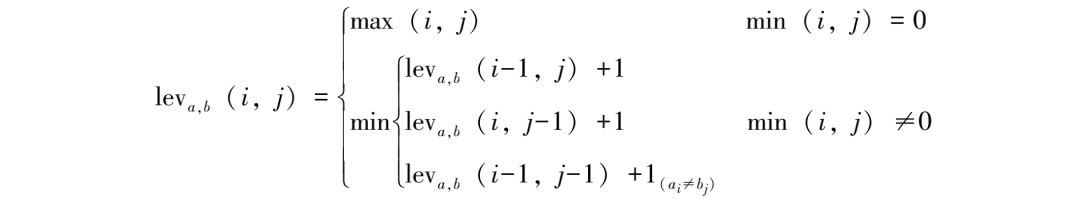
其中,a、b分别代表两个字符串(词),字符串的莱文斯坦距离表示为leva,b(i,j),即a字符串中前i个字符与b串中前j个字符之间的距离。如果计算完整字符串,即i=|a|,j=|b|,则leva,b(|a|,|b|)。Min(i,j)=0意味着i,j某个值为0,即a和b有一个字符串为空串,两个字符之间的距离就是其中一个字符串全部转换为另一个,是最大距离,即max(i,j)。如果Min(i,j)≠0,莱文斯坦距离leva,b(i,j)有3种状态,分别是删除、插入和替换。
限于篇幅,本文不讨论莱文斯坦距离的运算过程和算法,感兴趣的读者可参考Holman等学者的文章。下面我们讨论聚类方法。
四、聚类算法和树形图
聚类跟分类有不同的前提条件。所谓分类是指人们对事物有一定认识,积累了相关经验,可以依据事物的某些特征类别建立分类标准或者分类条件,从而对事物加以分类。聚类则完全不同,人们还未研究事物,只能依赖事物本身的内在结构和特征层次,对比多个事物之间的相似程度而实现归类。在这个意义上,聚类分析特别适用于语言或方言的关系判断,通过对不同语言词形和结构的相似性进行聚类分析,相似数据的数量越多,两种语言之间相似的程度越高,于是获得相似程度不等的语言集合簇(类),每个簇内的语言在属性特征上具有最大程度的相似性,不同簇的语言则有最大程度的不同属性。
数学上的聚类方法很多,本文不作详细阐述。但在理论上,就语言或方言来说,聚类方法的基本原理是将每两种语言或方言的成对词语相似系数最大或相异系数最小的集合聚成一类,形成相似程度不等的多个集合类,形成队列。譬如,如果A语言与X语言相似集合类的数量多于B语言,则A语言与X语言归为一类,B语言为另一类。这个分析过程扩展至C语言和更多语言,包括B语言跟C语言的相似数据数量比较,乃至更多语言比较,比较过程循环至全部参与语言为止,则获得所有语言相似程度关系,其结果可以绘成树状关系图,称为语言关系树形图。又由于历史语言学提出人类语言是一种自然传承和演化的现象,因此人们借鉴生物分类学之种系发生树(phyligenetic tree)概念,或称进化树或演化树(evolutionary tree),把语言之间相似程度计量关系树看作语言演化的渊源关系树,并以此观察和判断语言之间的亲缘关系,它们的分群和分类。
目前构建生物种系发生树或基因进化系统树的方法一般采用计算机来完成。构建进化树的软件较多,本文采用的是国际上运用较广的Mega软件,该软件是一款功能较为强大的分子进化遗传分析软件,全称是Molecular Evolutionary Genetics Analysis,特别适用于生物或基因计算遗传距离、构建分子系统树。Mega算法软件还提供了设置“树根”操作,可以帮助人们更进一步了解语言或方言之间在历史演化中的渊源关系。这有利于我们对西藏的语言和方言之间的关系进行推断。在下面的讨论中,我们会看到在根语言设定条件下西藏语言和方言呈现出的面貌。
五、自动分类实验与藏语方言的分布
(一)西藏语言和方言自动聚类树
在第二节采集的西藏语言和方言材料基础上,本文实验结果(聚类图形)如图1所示。此处先对其中约定的符号或代码加以说明。代码ZZ_W表示藏语卫藏方言,ZZ_K表示藏语康方言,ZZ_Q表示语言系属不明,ZS_和ZG_分别表示藏缅语苏龙系语言和义都系语言。代码之后用汉语拼音拼写语言或方言名称,例如ZZ_Wnimu表示藏语卫藏方言尼木话;ZS_bogaer,表示藏缅语苏龙系博嘎尔语;ZG_darang表示义都系语言达让语;ZZ_Qmangkangrumei表示芒康县系属不明的如美话。有时候,“ZZ_+拼音”直接表示藏缅语某语言,例如ZZ_cangladidong,藏缅语族仓洛语地东话。最后的数字表示该词属于斯瓦迪士第100词。
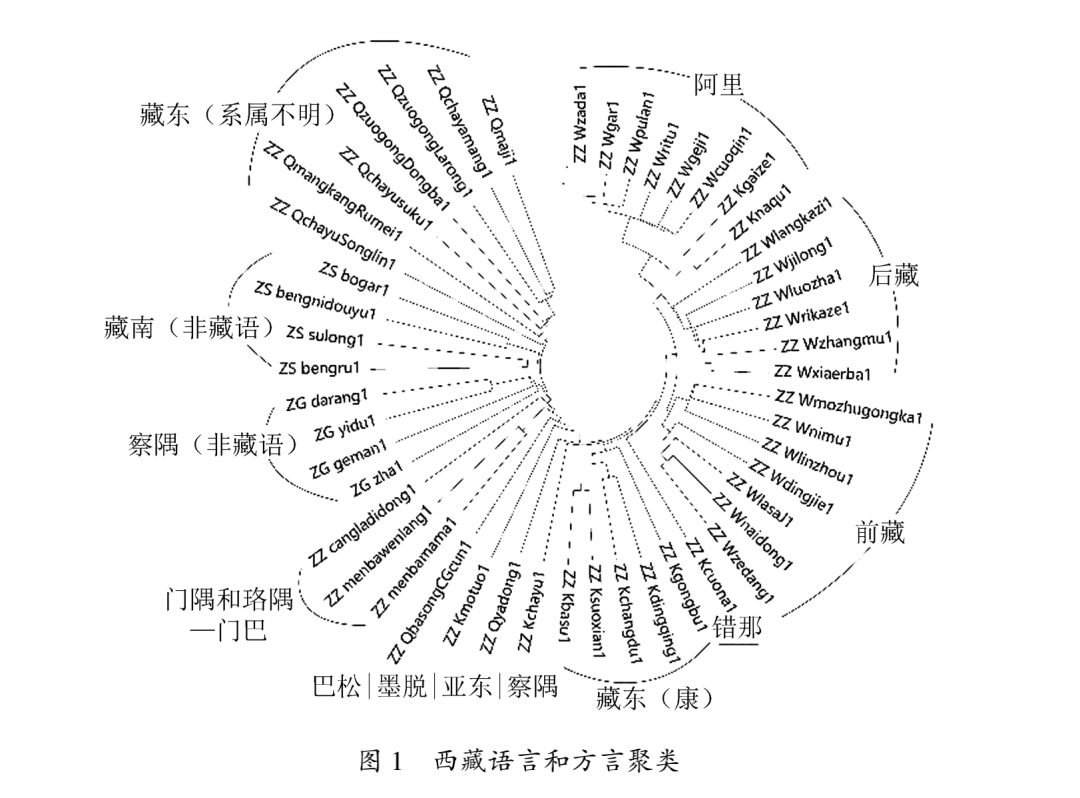
本次实验结果有多方面价值。观察图1,在不设立根语言(或者外类群)条件下,卫藏方言跟康方言清晰地分开来,而且卫藏方言内部十分明确又分出3个次级方言片:阿里次方言、后藏次方言、前藏次方言。根据《中国语言地图集·少数民族语言卷》,西藏语言地理上呈现二分状态,以林芝市工布江达县为过渡地带,往西是卫藏方言分布区域,往东则是康方言和其他非藏语区域。本文聚类图(图1)跟这幅语言分布地图十分吻合,顺时针方向,卫藏方言之后紧接着是藏东康方言片,然后有几个单列的方言,分别是察隅话、亚东话、墨脱话和巴松话。再之后就是其他语言:墨脱、错那、林芝等县的门巴语、仓洛语,察隅县的义都语、达让语、格曼语、扎话,以及墨脱、林芝、米林、隆子等县的博嘎尔语、崩尼语、苏龙语和崩如语。最后还有地理上沿金沙江西岸而下的察雅县、左贡县、芒康县直到察隅县等地的部分村乡土话,目前语言系属暂时不明,需要进一步甄别。
图1是完全没有人为干预的数学模型自动聚类结果,也就是单纯以语言自身属性特征的相似性为基础构建的算法结果。凡是形式、结构和特征相近的语言或者方言会自动形成聚类,因此我们也可以把这样的聚类结果理解为分类。如果结合前贤时彦的经验分类,例如瞿霭堂、格桑居冕、金鹏、张济川、布莱德利、尼古拉·图纳德尔,可以判断这项自动分类是相当可信的。我们在这里需要补充的只是对个别不一致的方言点作出新的解读,阐明不一致的原因。
(二)词汇借用改变方言归属
读者应该注意到本实验结果中卫藏方言阿里次方言聚类中包括了改则和那曲两个康方言,它们的位置处于阿里方言聚类树的最外侧。改则传统分类上划归康方言是有一定理据的。他们提出的理由有13条之多,其中语音层面的理据是:改则话有浊音(或带前置鼻音)、有清化鼻音[ȵ̥]和清擦音[ç ]、无鼻化复元音、无l和n辅音韵尾、声调调值跟其他阿里话有差别,也就是说,改则话具有康方言的一般特征。我们认为这些特征也适用于那曲话。下面以改则话为例进行讨论。
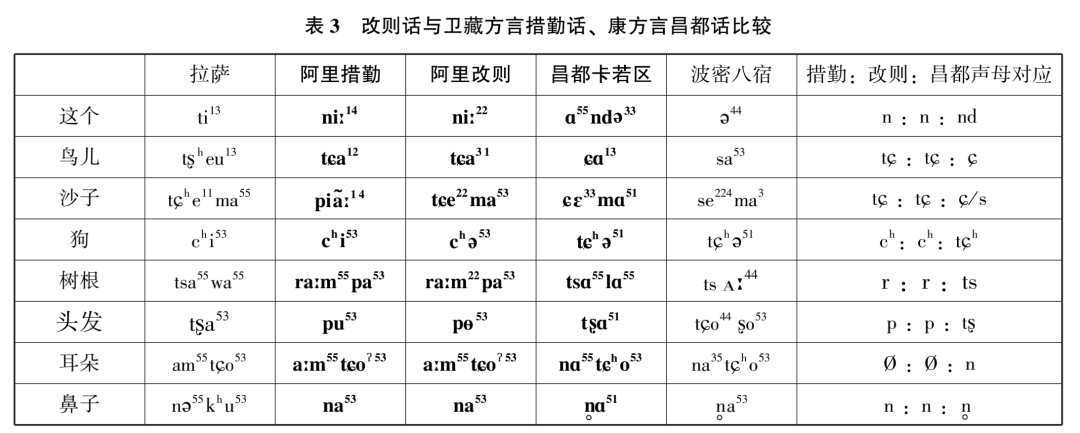
瞿霭堂、谭克让的叙述是正确的,一定有其他原因导致改则和那曲在本文自动聚类中归属于阿里次方言和更大范围的卫藏方言。地理上,改则和那曲两地处在昌都往西的藏北边沿康方言延伸地带,南面是卫藏方言。更具体地说,改则算是康方言延展的尽头,西面和南面的革吉县和措勤县均为阿里藏语,那曲南面林周、当雄和拉萨是前藏次方言。换句话说,这两个康方言点受到卫藏方言的严重影响。请观察表3呈现的词汇。
从这部分词语的读音来看(黑体词或语素),改则话与措勤话基本一致,通过比较卫藏方言的拉萨和措勤话、康方言的昌都话和八宿话可知,改则话有些词显然借用了措勤等地的词汇,跟康方言差别较大,不可能是语音演化导致的差异。例如,鸟儿,措勤为tɕa¹²,改则为tɕa³¹,昌都为ɕɑ¹³,该例“措勤(卫藏):改则:昌都(康)”的声母对比模式是[tɕ:tɕ:ɕ],塞擦音与擦音对立。再观察一例,鼻子,措勤作na⁵³,改则作na⁵³,昌都作n̥ɑ⁵¹,改则与措勤一致,都是鼻音声母,而昌都是清鼻音声母。“耳朵”这个词,拉萨作am⁵⁵ tɕo⁵³,措勤作aːm⁵⁵tɕoˀ⁵³,改则作aːm⁵⁵tɕoˀ⁵³,昌都为nɑ⁵⁵tɕʰo⁵³,波密为na³⁵tɕʰo⁵³,卫藏的拉萨、措勤与康方言的昌都、波密不同处甚多,但改则与措勤一致,应该不是语音演变导致的,而是改则直接借用了措勤的词汇。由此我们知道,词汇借用,特别是常用词汇借用是判断语言或者方言之间关系的一个重要标准。
(三)方言间的断点致使归属不确定
图1有几个调查点数据在聚类中出现孤立单列状况:察隅、墨脱、错那、亚东、巴松。经反复考察,有两方面原因,一是这些方言处在多语言或多方言交汇地域,语音词汇受到影响,同时包含了两种不同语言或方言的特征;二是本文收集的调查点数量稍显稀疏,它们跟其他方言点中间缺少链接环节。不过,各个调查点又有不同情况。察隅、墨脱、错那这3个藏语方言都处在藏语分布的边缘位置,其中察隅话与周边义都、达让、格曼等几种非藏语语言相互接触,墨脱话、错那话与门巴语、仓洛语、博嘎尔语等也相互影响,这样的语言接触有可能给藏语方言带来异类词汇语音,值得细化研究。
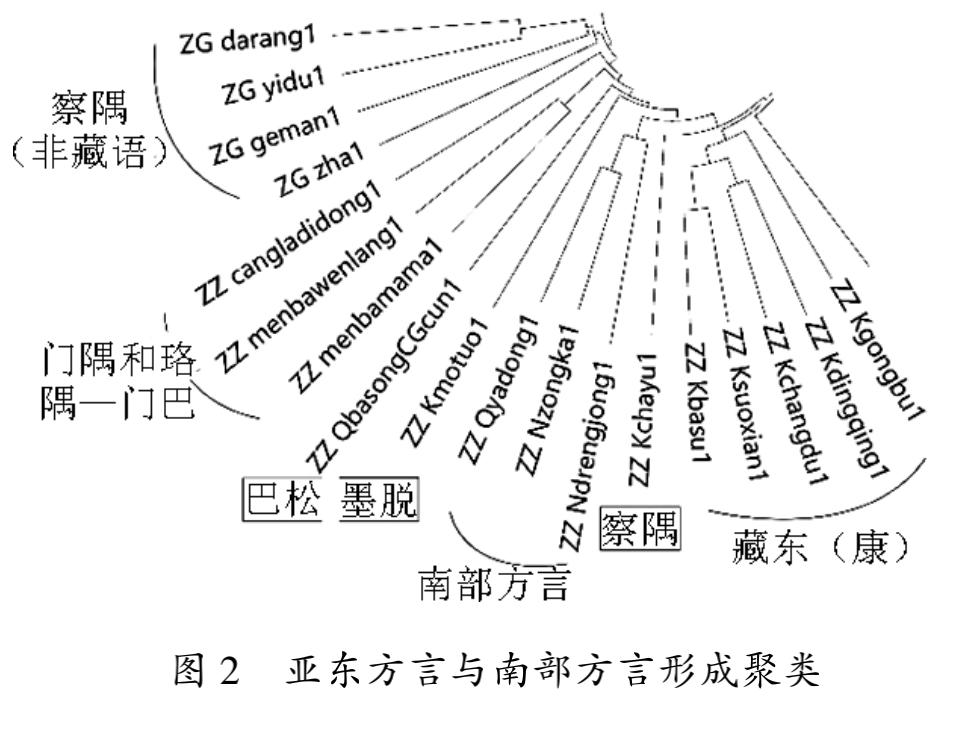
亚东话情况略有不同,格桑居冕、瞿霭堂、劲松将其归入后藏次方言,但是我们也注意到西义郎将之划归南部方言。南部方言是国外部分学者提出的,特指不丹王国等境外某些语言或者藏语方言。张济川提出:“亚东位于卫藏方言区的边沿,与不丹、锡金相邻。跟卫藏方言的前后藏土语和南部方言宗喀话(不丹)比较,既与后藏土语有一些共同点,也与宗喀话有一些共同之处。从现有材料来看,亚东藏语似处于卫藏方言和南部方言的过渡带。”为了判断亚东方言的归属,我们将境外的宗喀语(Dzong kha)和德容炯语(Dreng jong)数据放入实验,结果如图2所示,构成南部方言群。图1亚东话只是因为缺失其他南部方言点造成地理分布的断点而单列。如果结合西藏和不丹王国历史来看,这项实验证明,南部方言以及境外一些藏系语言是逐步从西藏扩散开来的。
(四)语言置换作为归属的深层原因
上文明确指出,巴松话、察隅话、墨脱话、错那话的单列与语言的相互接触有关,现在来具体分析。
巴松话是瞿霭堂等调查记录,认为是藏语卫藏方言次级方言(土语)。与此同时,瞿霭堂提出,为什么卫藏方言其他方言点的人,甚至邻近说工布话的人也听不懂巴松话呢?他认为是词汇差异造成的。词汇差异背后更深层的原因则是:巴松话“是原来使用一种可能与门巴语接近的语言的人,受卫藏方言影响,换用语言的结果,只是保留了一个非藏语的词汇底层”。我们同意瞿霭堂的分析,只是按照他的分析,巴松话(100多个词汇与川藏其他语言比较)“大部分非同源词,限于条件还没有找到来源,需要进一步研究”。这意味着巴松话的归属还需要作进一步探索。巴松话在本实验中处在与其他藏语方言相关又未进入已确定系属组群状态,这正反映了瞿霭堂分析之精准。
察隅话、墨脱话、错那话所处位置都是与非藏语语言共存区域,察隅话主要与义都语、达让语和格曼语相互接触,墨脱(达木)话和错那话与门巴语和仓洛语交错。这3个调查点有两种系属归类的可能,一是跟巴松话一样来自早期其他语言的转换,二是原属藏语,借用了周边其他语言的词汇。结果,它们在自动聚类图中处于单列状态。但从语言的社会功能来说,藏语作为当地强势语言,第一种解释更可信一些。我们暂时认为这几个调查点的归属存疑。
六、西藏的非藏语及其分类
上文指出,聚类方法蕴含了系统发生树理论,可以模拟语言演化距离和层级。所以,本文进一步实验添加了“树根”或外类群。经我们测试,选择泰米尔语(Tamil)为根语言比较稳定。实验结果如图3所示:
观察图3聚类树,首先就发现苏龙语和崩如语远离藏语及其方言(参看第五节),它与藏语之间层级和距离上还隔着义都系、博嘎尔系、门巴和洛巴族的语言,以及一些系属不明的语言。据研究者介绍,苏龙语和崩如语主要分布在西藏山南地区隆子县以南比夏一带的村庄,分别有3000—4500人和约2000人,但基本处于印度实际控制区内,在笔者调查的村寨只居住极少数个体。为此,本文收集了西方学者有关苏龙语和崩如语的资料,并纳入本系统测试,参见图4。


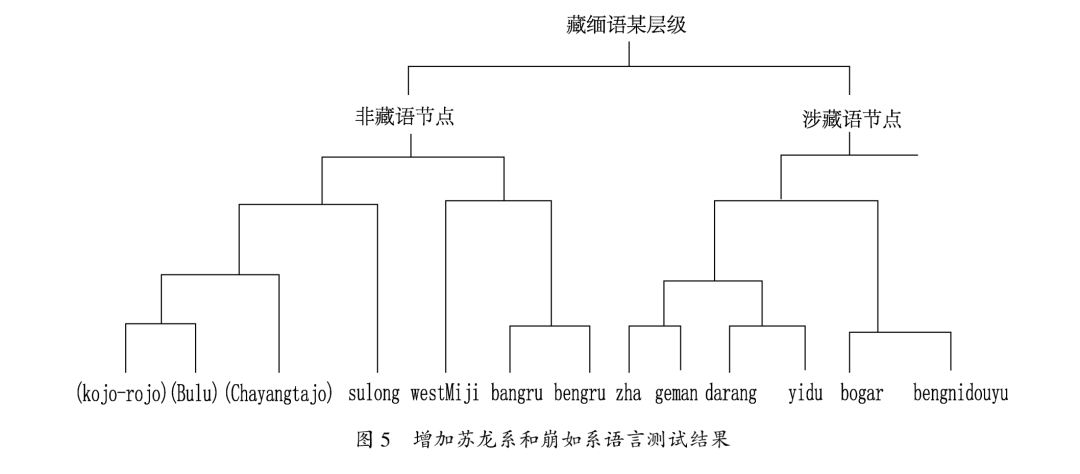
测试结果不出意料,增加西方学者采集的苏龙系语言(称为Puroik,3个方言点:Kojo-Rojo、Bulu、Chayangtajo)和崩如系语言(两个方言点:westMiji、Bangru),发现它们的确与本文数据形成聚类,跟藏语没有直接亲缘关系,聚类的节点处在根语言之下一个两分链接点的非藏语方(图5),可能是藏缅语族的一种语言。
回到图3,我们知道,聚类树图一定意义上递进反映各组或各个语言之间的亲疏关系(此图由下而上),越往上距离根语言关系越远,换言之,越靠近根的语言或语群,相互间关系越近,越靠近顶部的语言分化越晚。不过,此时讨论的“亲疏”尚未排除语言接触和词语借用造成的关系。
图3中与藏语最靠近的语言是门巴族语言。20世纪80年代初,学术界发布了《门巴、珞巴、僜人的语言》。主要涉及藏东南区域的非藏语语言。之后,语言简志丛书陆续出版,初步呈现出西藏的语言多样性状况。进入21世纪后,孙宏开教授主编的中国新发现语言研究丛书出版了格曼语、义都语、达让语、苏龙语等专著,还发表了扎话(语)、崩如语等描写性文章,当时还发现了松林语等未曾描述的语言,成果并于近年出版。从新发现语言陆续出版角度来看,人们逐步了解到西藏地方,特别是藏东南区域是很典型的语言多样性区域。
实际上,西藏的部分非藏语语言由来已久,最知名的是门巴族语言。门巴族主要居住在墨脱县、错那县以及错那县以南的邦金和门达旺地区(这部分目前处在印度非法实控区),说两种不同的语言,错那县勒布区和墨脱县文浪乡说门巴语,墨脱县和林芝县东久区说仓洛语。门巴族与藏族的历史渊源悠久,早在吐蕃时期就已往来。著名的唐蕃会盟碑(或称长庆会盟碑,公元823年)记载曰:“此威德无比雍仲之王威严煊赫,是故,南若门巴、天竺,西若大食,北若突厥拔悉蜜等虽均可争胜于疆场,然对圣神赞普之强盛威势及公正法令,莫不畏服俯首,彼此欢忭而听命差遣也。”一千余年来,门巴族与藏族交错居住,相互通婚,文化相融,甚至17世纪在门巴地区出生的仓央嘉措被认定为五世达赖喇嘛的转世灵童。语言上,门巴族人基本会说藏语,可见门巴语受藏语影响非同一般,藏语借词极为丰富,因此在本实验聚类图上相当靠近当地藏语方言。再以实例来说,“嘴”,仓洛语地东话说[no¹³waŋ¹³],门巴语文浪话说[kʰɑ⁵⁵],后者应来自藏语借词;比较:昌都卡若话说[kʰɑ⁵¹],拉萨话说[kʰa⁵⁵]。再如“多”,仓洛语说[sak¹³po⁵⁵]或[ca⁵⁵ma¹³],门巴语麻玛话说[maŋ³⁵po⁵³],后者明显来自藏语;比较:昌都话说[mon³³po⁵¹],拉萨话说[maŋ¹³ko⁵⁵]。门巴语借用藏语词汇是最典型的语言接触现象。
门巴族语言之外,西藏东南部的察隅和珞隅地区还有多种非藏语的其他藏缅语言。正如费孝通先生所说,中国民族走廊的南端可能一直绕到察隅和珞隅。目前已经探明,察隅县主要有义都语、达让语、格曼语和扎话。前三者在早期文献中被称为“米什米”,这也有历史记载。据藏族历史文献《贤者喜宴》所录,“如是,东方之咱米兴米(རྩྭ་མི་ཤིང་མི)、南方之洛(གློ)与门(མོན)、西方之香雄(ཞང་ཞུང)及突厥(གྲུ་གུ)、北方之霍尔(ཧོར)及回纥(ཡུ་གུར)等均被收为属民。遂统治半个世界”。其中,“米兴米”指的就是达让、格曼、义都语言群体,而“咱”(རྩྭ)应该特指扎话语言群体。
据上述研究,义都语和达让语关系十分紧密,具有同一来源。格曼语则属于另一支系语言,扎话也可能底层是格曼语,借用了大量藏语词汇,已是藏语化的格曼语。不过,在藏缅语层次上,这几种语言目前系属不确定,本文暂时建立一个分支,统称义都系语言。据研究,义都语母语人属于珞巴族,而珞巴人分布广泛,从察隅往西至隆子县,北邻雅鲁藏布江,南至整个珞隅地区分布着十数个珞巴族部落,包括操崩尼语和博嘎尔语人。崩尼语和博嘎尔语也是藏缅语族语言,它们与藏语关系十分密切,在图3聚类图中位置处于门巴语言和义都系语言之间。
最后需要讨论的是目前归属完全不明的一批地方话。主要有:左贡县东坝话、拉茸话,芒康县如美话,察隅县素苦话、松林话、芒话。这些分布在藏东和藏东南的地方话是使用者的母语,一般只在家庭和村寨使用。他们是藏族,因此使用者一般都是双语人,外出使用当地康方言。在本项实验中,这些地方话处在藏语卫藏方言和康方言聚类之外,是否为独立语言尚需甄别。期待学术界持续开展研究。
七、结语
本文对西藏语言多样性的描述,一方面是一种回顾和梳理,另一方面则是借助数学模型和现代计算机算法技术提出问题,让人们了解西藏文明的悠久和语言的多样性与复杂性,以便更深入地开展调查和研究。
就技术角度来说,本文的讨论还可以进一步深化,特别应在以下几方面取得突破:
第一,为克服断点导致的地理分布不连续现象,应扩充语言或方言调查点,最好能完整地覆盖西藏自治区各地(市)、县(区),尤其是东部和东南部区域。
第二,鉴于西藏自治区语言和方言相互之间广泛存在词汇借用情况,可以尝试在基本词汇之外增加一批常用性或一般性词汇。
第三,藏族语言文化历史悠久,对整个喜马拉雅山区域族群和语言都有重要影响。为此,对西藏语言多样性的调查可以扩展到整个喜马拉雅区域。
版权所有 中国藏学研究中心。 保留所有权利。 京ICP备06045333号-1
京公网安备 11010502035580号



